Durable Execution
How would you code if your app couldn't fail? Durable Execution helps you build reliable apps that keep working, even when systems fail or your app crashes. It tracks progress and state, so your work isn't lost and processes keep running. Whether your app faces a service outage or unexpected shutdown, Durable Execution makes sure it picks up where it left off, with no progress lost. This reliability lets your app handle disruptions and keep delivering results.
You handle the flows and not the recovery
With Durable Execution, you focus on your workflows and business logic, not on handling errors. The following code is real and works:
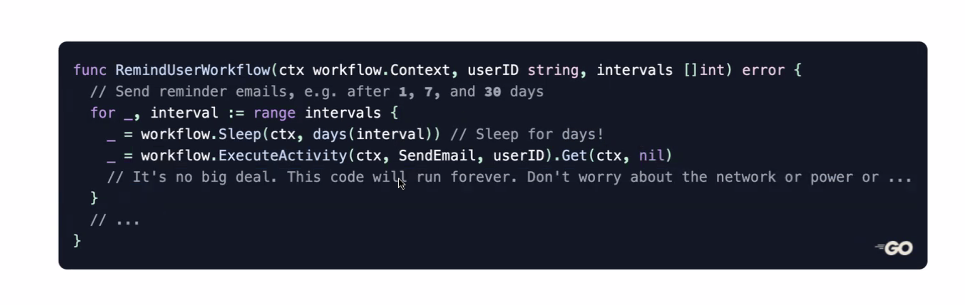
This means you end up with code that's simpler and more durable:
-
Simpler code. Move handling for abnormal conditions like network and hardware errors out of your logic. You don't need it with Durable Execution.
-
Run forever. You don’t need to worry about crashes or system outages, even over years or decades.
-
Runs under every condition. Durable Execution separates progress tracking from implementation details.
-
Deploy and run at the same time. Durable Execution makes sure each run follows the original logic and pathway. You can ship updates and patches without changing outcomes for your existing long-running processes.
It's really that easy.
The value proposition
Durable Execution offers a powerful solution for building reliable and scalable applications. It ensures that your workflows continue seamlessly, even when facing failures or disruptions. Durable Execution is:
-
Stateful and persistent: Durable Execution tracks progress and maintains state even when your service restarts or experiences failures. It stores checkpoints in external databases and logs, ensuring your system handles outages or crashes without losing progress.
-
Fault tolerant: Durable Execution handles failures automatically, keeping tasks running even when parts of your system go down. When a failure occurs, it recovers tasks without interrupting your entire application.
-
Designed to separate concerns: Durable Execution separates task orchestration from infrastructure management. This allows your app’s logic to focus on business processes. Your code concentrates on application-level logic, like managing fraud alerts or insufficient funds in a banking app. Durable Execution handles state and errors related to platform issues, such as network outages or infrastructure failures.
-
Won't repeat work: Durable Execution ensures tasks are not repeated unnecessarily. When a task fails, it retries it using policies designed to ensure success without duplicating work. This keeps the process consistent, eliminating redundant work even when errors arise.
-
Naturally recoverable: Even in worst-case scenarios, Durable Execution recovers execution without losing progress. Moving to new hardware or service center deployments won't interrupt your workflows.
-
Inherently observable: Durable Execution makes the state, health, and progress of your app fully visible. It tracks tasks in real time, so you see progress, failures, and retries as they happen.
Temporal and Durable Execution
When using the Temporal Service, Durable Execution works by separating state and progress (called an Event History) from the code it executes. This abstracted oversight (called "orchestration") happens on a server using a persistent state and progress data store.
Temporal's approach offers specific advantages:
-
Scale as needed. Durable Execution scales with your business. Each execution is a unique progress abstraction, so you just add more computing resources to match your needs. This lets you managing additional work without affecting the consistency or reliability of your execution process.
-
Low latency. Durable Execution is fast and reliable. It processes tasks quickly and efficiently, ensuring short and predictable response times.
Durable Execution and self-healing issues
Imagine developing a system to handle reimbursements for your employees. Consider ways your process might get blocked and resolved. For example:
-
Your finance manager goes on vacation and can't approve. Set a time-out policy and use alternate routing (another coworker) or messaging ("Hey, I'll be out of the office") so every reimbursement gets addressed in time.
-
The direct deposit with the reimbursed funds failed. There might be an outage at the recipient's bank. If you've set a retry policy to avoid overloading or abusing the API provider’s capacity, you can keep trying until the deposit works. After giving the provider time to recover, you can run your code again and succeed.
-
The printer for paper checks is jammed or out of paper. Not every employee opts into direct deposit. You may need someone to manually walk over and take care of the issue before the check can be cut and sennt.
With Durable Execution, any problem that recovers automatically over time isn’t really a problem. With Durable Execution, you have a built-in way to retry your task later. Durable Execution keeps your tasks alive and moving.
That's not to say that all tasks will heal over time. For example, one of your service providers might go out of business. When you run into outlier cases where something is truly broken, you need a solution like Temporal.
With Temporal, you can patch your code to use a new provider and safely deploy your fixes. You can then replay your flow's execution history to pick up real-world changes, allowing it to complete your process without losing or repeating work.
Temporal capably handles both the self-healing and catastrophic scenarios.
Temporal requirements
Temporal's use of Durable Execution depends on a few critical factors to ensure you won’t lose or repeat work. Temporal uses a technique known as History Replay, which depends on the following:
-
A durable store: Event History must be saved durably using your server's persistent store. A workflow run, or its abstract execution, must persist forever or until you explicitly no longer need it.
-
Idempotency: Idempotency means you design tasks to succeed once and only once. An idempotent approach prevents process duplication, like withdrawing money twice or accidentally shipping extra orders. Run-once actions maintain data integrity and prevent costly errors. Idempotency keeps operations from producing additional effects, protecting your processes from accidental or repeated actions, ensuring reliable execution.
-
Determinism: Durable Execution stores and tracks every workflow as an abstract entity. If you need to restart the process under extreme circumstances, that process must align with the original run. You can't change a random number or a real measurement (like temperature, time, or location) from the first run. If you do, you can't just pick up from where you left off because the work no longer matches the earlier history.
Durable Execution requires your workflow code to be deterministic. Every time it runs or is replayed, the outcomes must be the same. This is the only way centralized control can provide all of Durable Execution's features.
Does this mean you can’t use random numbers or run your work on different days or in different environments? Of course not. It means your code must reliably pick up from where it left off without changing the past in any logical way. This is called determinism. It ensures that given the same starting conditions, your workflows behave identically during each execution. Your results are reliable and assured.
Wrap-up
Durable Execution helps you build reliable and scalable applications. It keeps your workflows running smoothly, even through system failures or disruptions. By separating your application logic from task orchestration, Durable Execution ensures that your processes are consistent, reliable, and error-free.
With automatic recovery, Durable Execution guarantees that tasks complete without losing or repeating work. It simplifies your code, lets you scale easily, and ensures that your app can handle any challenges along the way. Durable Execution makes sure your critical processes keep moving forward, no matter what.